No, you can't control for that
EARLIER THIS month, Ezra Klein wrote a post about the use of statistical "controls" in academic studies. If statistics isn't your thing, then the background: "controls" are just the list of variables you include in your statistical model other than the the variable whose effect you are attempting to estimate. Klein says
"You see it all the time in studies. "We controlled for..." And then the list starts. The longer the better. Income. Age. Race. Religion. Height. Hair color. Sexual preference. Crossfit attendance. Love of parents. Coke or Pepsi. The more things you can control for, the stronger your study is—or, at least, the stronger your study seems. Controls give the feeling of specificity, of precision."Is this really what people think of controls? Do the study authors put this much faith in the value of controls? I'm genuinely baffled if they do.
Klien went on to mention the downside of including too many controls
"But sometimes, you can control for too much. Sometimes you end up controlling for the thing you're trying to measure."--basically, if the thing you care about affects the things you control for which in turn affect the outcome you care about, then your estimate is missing a portion of the effect you care about. But there's a deeper problem with the sentiment that Klein described. Adding the right controls won't do anything to guarantee that your estimate is causal. And the best study designs are the ones that minimize the number of control variables needed. First, let's examine what controls variables are for.
Suppose you want to estimate the effect of variable X on variable Y. The third variable Z also affects Y but also affects X so that X and Z are correlated. I get complaints whenever I put math on here, so here's a graph of the causal relationships: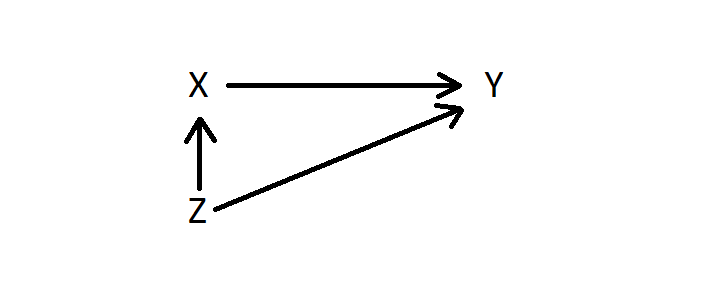
- the control variable is correlated with your independent variable of interest, and
- the control variable has a non-zero effect on the outcome variable.
Frequently, though, I notice commentators and study authors perform a subtle bait-and-switch when they talk about controlling for various factors. For example, suppose we want to estimate the effect of the number of police officers on crime rates. Crime rates vary by neighborhood, and governments typically assign more police officers to higher crime neighborhoods. This situation sounds superficially like the paragraph above: two regressors, neighborhood and number of police, which are correlated with each other and which both affect crime rates. A naive researcher might regress police on crime, controlling for neighborhood, and claim that the estimate is causal. But it's not! There's been a subtle shift from discussion of neighborhood effects given a certain number of police on crime to the effects of crime on the number of police in those neighborhoods. There's no way to control for the latter. If you actually did this you'd probably conclude that police presence has virtually no effect on crime, but that's wrong.
The causality chart in the example above actually looks like this:
While you can certainly have both endogeneity and omitted variables bias, in my simulation with endogeneity added, the estimate was wrong 100 percent of the time with Z in the regression, versus 100 percent of the time with Z omitted.
What we need to get a true causal estimate of the effect of police on crime is to identify a source of exogenous variation in police levels. This is different than adding control variables. One strategy would be to perform an experiment by randomly assigning police officers to neighborhoods. That would eliminate the endogeneity because randomized police presence would mean that crime rates have no effect on police presence, so it is safe to attribute variation in crime rates to the variation in police levels. Incidentally, we don't actually have to "control" for neighborhood effects now, because with perfect randomization neighborhoods are no longer correlated with levels of police, so there's no omitted variables bias either. This is what I mean when I say that the best study designs are the ones that minimize the number of control variables--the closer to random our treatment variable is, the less of both endogeneity and omitted variables bias we are likely to face.
For the most part, having a very long list of control variables is actually evidence of the weakness of the underlying study design. Controlling for these variables is better than not when there is risk of omitted variables bias, but a design that has such risks is considerably weaker than one that does not. Bottom line: be suspicious whenever a paper says "controlling for ____". There's a good chance you can't actually control for that.
